How Kafka Works
by Elliot Chen, a system designer
In software development, Kafka is often used to build real-time data pipelines and streaming applications. It allows you to publish and subscribe to streams of records, store those records in a fault-tolerant manner, and process them in real-time. It's particularly popular for handling large volumes of data in a scalable and efficient way.
Why fast in general
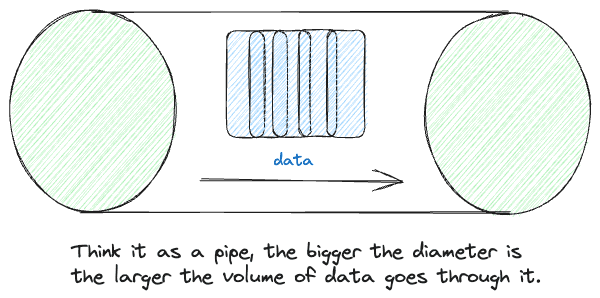
Kafka is designed to be fast and highly performant, in a nutshell, Kafka's initialized a very large pipe, the volume of data goes through it as the diameter gets larger for even more data processing.
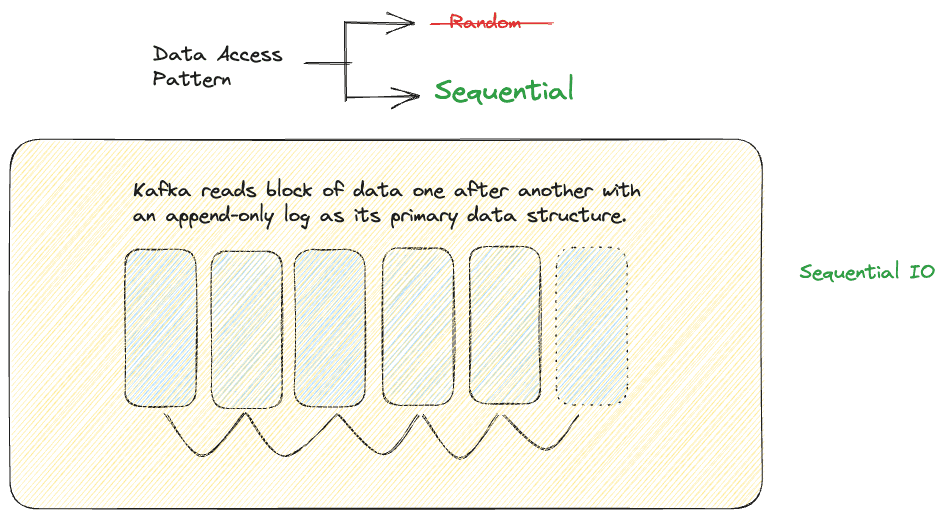
SequentialIO
Zero-copy principal
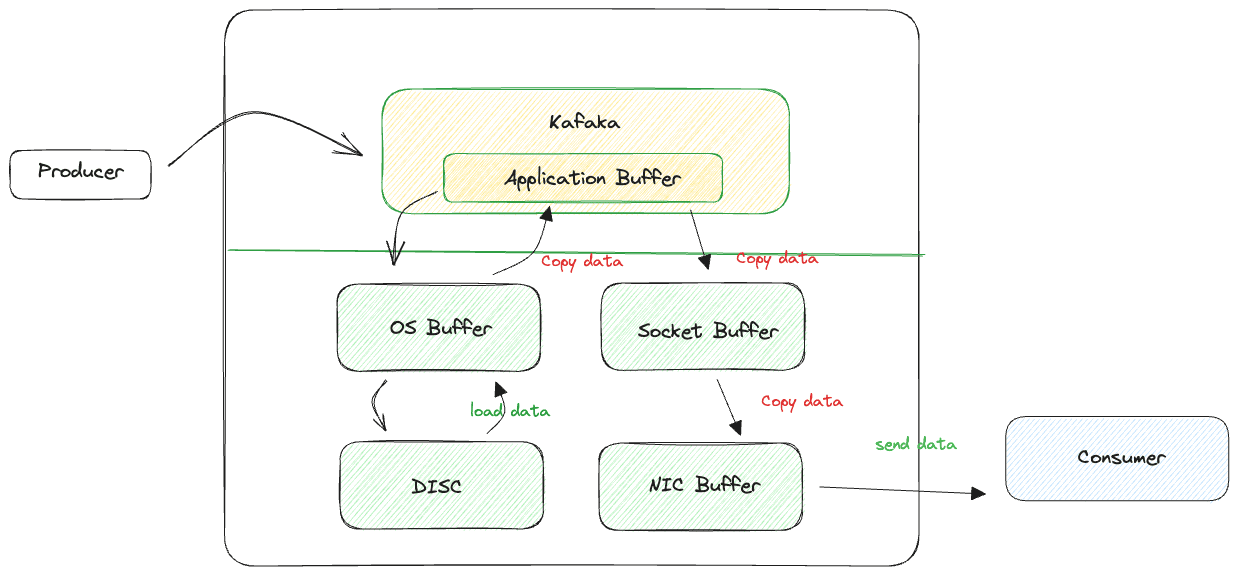
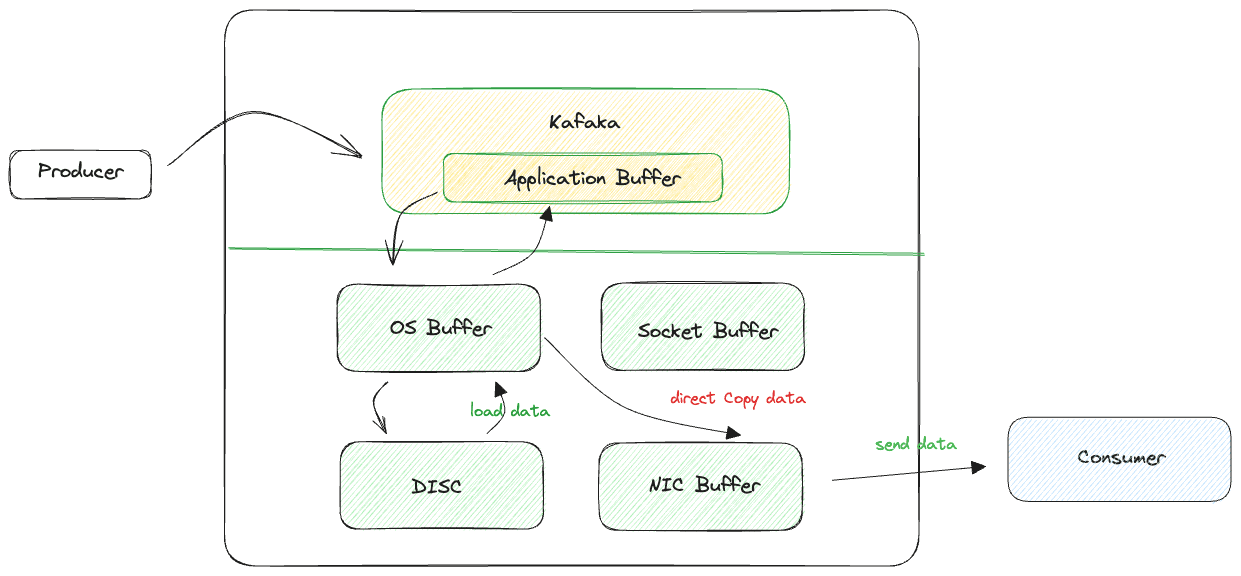
The concept of "zero copy" is often associated with how Kafka achieves efficient and high-throughput data transfer between producers, brokers, and consumers. Kafka employs a zero-copy principle to optimize data transfer without unnecessary copying of data, which can improve overall performance and reduce resource utilization.
By applying the zero-copy principle at various stages of data transfer, Kafka can achieve high throughput, low latency, and efficient use of system resources. It's important to note that the effectiveness of zero copy may vary depending on the operating system and hardware, but Kafka's design takes advantage of this principle whenever possible to optimize data transfer and processing. This contributes to Kafka's suitability for handling large volumes of real-time data streams in a performant and scalable manner.